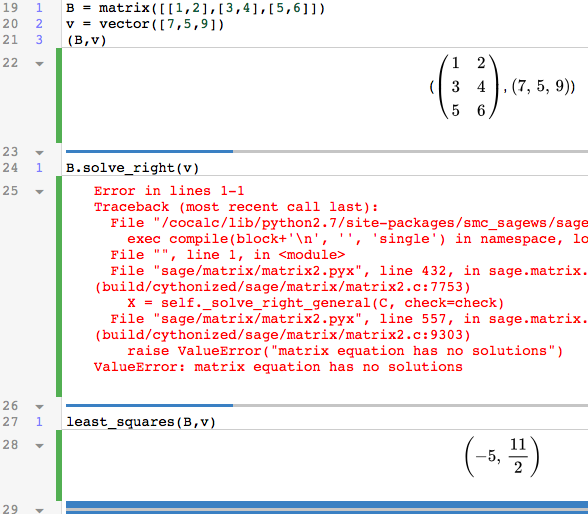
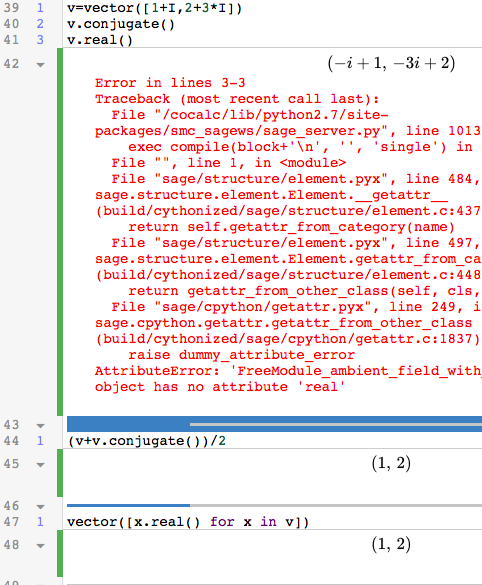
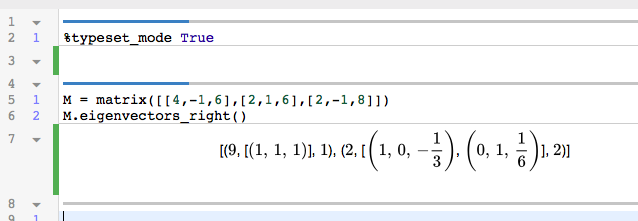
The topic this week is the Singular Value Decomposition. In class, I talked about an example using weather data; we’ll walk through that example again here.
The basics
Given a matrix A, A.singular_values() returns the singular values of A, and A.SVD() gives the singular value decomposition. There’s a wrinkle, though: Sage only knows how to compute A.SVD() for certain kinds of matrices, like matrices of floats. So, for instance:
A = matrix([[1,2,3],[4,5,6]])
A.SVD()
gives an error, while
A = matrix(RDF,[[1,2,3],[4,5,6]])
A.SVD()
works fine. (Here, “RDF” stands for “real decimal field”; this tells Sage we want to think of the entries as finite-precision real numbers.)
The command A.SVD() returns a triple (U,S,V) so that A=USV^T; U and V are orthogonal matrices; and S is a “diagonal” (but not square) matrix. So, the columns of U are left singular vectors of A, and the columns of V are right singular vectors of A.
I find the output of A.SVD() hard to read, so I like to look at its three components separately, with:
A.SVD()[0]
A.SVD()[1]
A.SVD()[2]

As always, you can get some help by typing
A.svd?
Getting some data
We’ll compute an SVD for some weather data, provided by the National Oceanic and Atmospheric Administration (NOAA). (The main reason I chose this example is that their data is easy to get hold of. Actually, lots of federal government data is accessible. data.gov keeps track of a lot of it, and census.gov has lots of data useful for social sciences.)
To get some data from NOAA, visit the National Climate Data Center at the NOAA, select “I want to search for data at a particular location”, and then select “Search Tool”. Then hack around for a while until you have some interesting data, and download it. This took me several tries (and each try takes a few minutes): lots of the monitoring stations were not reporting the data I wanted, but this wasn’t obvious until I downloaded it. That’s how dealing with real-world data is at the moment; in fact, the NOAA data is much easier to get hold of than most.
You want to download the data as a .csv (comma-separated values) file. Here is the .csv file I used: weatherData.csv. My data is from a monitoring station at Vancouver airport (near Portland), with one entry per day of the year in 2015 (so, 365 entries total), recording the amount of precipitation, maximum temperature, minimum temperature, average wind speed, fastest 2 minute wind speed, and fastest 5 second wind speed.
You can open this csv file with Excel or any other spreadsheet. More important for us, Python (and hence Sage) imports csv files fairly easily.
To import the file into Sage, save it to your computer, and then upload it to Sage Math Cloud by clicking “New” (file) button. Here is code that will import the data into a Sage worksheet, once it’s been uploaded to Sage Math Cloud:
import csv
reader=csv.reader(open('weatherData.csv'))
data = []
for row in reader:
data.append(row)
(If the filename is something other than weatherData.csv, change the first line accordingly.) The result is a list of lists: each line in the data file (spread sheet) is a list of entries, and ‘data’ is a list of those lines. Type
data[0]
data[1]
to get a feeling for what the data looks like.

Converting the data to vectors
We want to:
- Extract the numerical data from ‘data’, creating a list of vectors (instead of a list of lists).
- Compute the average of these vectors.
- Subtract the average from the vectors, creating the “re-centered” or “mean-deviation’ vectors.
- Turn these re-centered vectors into a matrix A.
- Compute the singular value decomposition of A.
- Interpret the result, at least a little.
Step 1. The first real line of data is data[1]. Let’s set
v1=data[1]
v1
The numerical entries of v start at fourth entry, which is v[3] (because Sage counts from 0). To get the part of v starting from entry 3 and going to the end, type
v1[3:]

We want to do this for each line in data, from the second line (line 1) on. We can create a new list of those vectors by:
numerical_vectors = [x[3:] for x in data[1:]]
(As the notation suggests, this creates a list consisting of x[3:] for each line x in data[1:]. This is called list comprehension, (see also Section 3.3 here) and it’s awesome.)
This is still a list of lists. We want to turn it into a list of vectors, in which the entries are real numbers (floating point numbers). A similar command does the trick:
vecs = [vector([float(t) for t in x]) for x in numerical_vectors]
Check that you have what you expect:
data[1]
vecs[0]

Step 2. Computing the average. Note that there are 365 vectors in vecs. (You could ask Sage, which the command len(vecs).)
M = sum(vecs) / 365
Step 3. Again, this is easiest to do using list comprehension:
cvecs = [v - M for v in vecs]
Step 4. This is now easy:
A = matrix(cvecs)
Cleaning the data
The NOAA data is pretty clean — values seem to be pretty reasonable, and in particular of the right type — except that lots of values tend to be missing. Sadly, those missing values get reported as -9999, rather than simply not being present. So, it’s easy to get nonsense computations. For example, if we just type:
A.SVD()[2]

(which gives us the matrix of right singular vectors) something doesn’t look right: many of the entries are very small. Examining our vectors, here’s the problem:
cvecs[19]
data[20]
The last entry here is missing, and reported as -9999.
Dealing with missing data is a hard problem, which is receiving a lot of attention at the moment. We will avoid it just by throwing away the columns that have some missing data. That is, let’s just consider the four columns (precipitation, max temperature, min temperature, average wind speed). I prefer to create new variables with the desired vectors, rather than changing the old ones:
numerical_vectors2 = [x[3:7] for x in data[1:]]
numerical_vectors2[17] #Let's see what one looks like.
vecs2 = [vector([float(t) for t in x]) for x in numerical_vectors2]
M2 = sum(vecs2) / 365
cvecs2 = [v - M2 for v in vecs2]
cvecs2[17] #Let's see what this looks like
A2 = matrix(cvecs2)

SVD and visualizing the result
Now, let’s look at the singular values and vectors.
A2.singular_values()
A2.SVD()[2]

Notice that there’s a pretty big jump between singular values. The third singular value, in particular, is a lot smaller than the first three, so our data should be well approximated by a 3-dimensional space, and even just knowing a 1-dimensional projection of this data should give us a reasonable approximation. Let’s make a list of the singular vectors giving these projections, and look at them a bit more.
sing_vecs = A2.SVD()[2].columns()
sing_vecs[0]
I get roughly (0.0037, -0.8389, -0.5435, -0.0298). This vector stands for (precipitation, maximum temperature, minimum temperature, average windspeed). This says, for instance, that when the maximum temperature and wind speed also tend to be below average, and the amount of precipitation tends to be above average. (This is consistent with my experience of winter in Oregon, except maybe for the wind speed which is a little surprise.)
The singular vectors give us new coordinates: the new coordinates of a (re-centered) vector are the dot products with the singular vectors:
def coords(v):
return vector([v.dot_product(w) for w in sing_vecs])
If you look at the coordinates of some of our re-centered vectors, you’ll notice they (almost always) come in decreasing order, and the third is very small. For instance:
coords(cvecs2[17])

(That’s the weather for January 18 that we’re looking at, by the way.)
We can use the coordinates to see how well the data is approximated by 1, 2, and 3-dimensional subspaces. Let’s define functions which give the 1-dimensional, 2-dimensional, and 3-dimensional approximations, and a function that measures the error.
def approx1(v):
c = coords(v)
return c[0]*sing_vecs[0]
def approx2(v):
c = coords(v)
return c[0]*sing_vecs[0]+c[1]*sing_vecs[1]
def approx3(v):
c = coords(v)
return c[0]*sing_vecs[0]+c[1]*sing_vecs[1]+c[2]*sing_vecs[2]
def error(v,w):
return (v-w).norm()
For example, the approximations for January 18, and the errors are:
v = cvecs2[17]
v
approx1(v)
error(v, approx1(v))
approx2(v)
error(v, approx2(v))
approx3(v)
error(v, approx3(v))

One way to see how good the approximations are is with a scatter plot, showing the sizes of the original vectors and the sizes of the errors between the first, second, and third approximations, for each day in the year:
list_plot([v.norm() for v in cvecs2])+list_plot([error(approx1(v),v) for v in cvecs2], color='red')+list_plot([error(approx2(v),v) for v in cvecs2], color='orange')+list_plot([error(approx3(v),v) for v in cvecs2], color='black')

Blue is the length of the original re-centered data. The red, orange, and black dots are the errors in the first, second, and third approximations. The fact that they get closer to 0, fast, tells you these really are good approximations.
Further thoughts
The data we’ve been looking at is heterogeneous — it doesn’t really make sense to compare the magnitude of the wind speed to the magnitude of the temperature. So, perhaps we should have renormalized all of the components in our vectors first to have standard deviation 1, say, or maybe done something else more complicated. (If we renormalize, we’re blowing up small variations into big ones; is this what we want?) At the very least, our visualization of the errors is a little silly.
Another unsatisfying point is understanding what the second and third singular vectors are telling us, other than that they capture most of the information in the original vectors.
Finally, again, our way of handling missing data is thoroughly unsatisfying. (This is an active area of research, with applications ranging from genomics to music recommendations.)