 Spatial Modeling – Julie Stringham
Spatial Modeling – Julie StringhamThis assignment builds off of the observations made on our previous model, and explores the effects of parameter changes in depth. Here, we conduct a parameter sweep which shows us how the change in value for each parameter affects the spatial patterns we detect.
Part 1: What is the difference between a variable and a parameter?
Variables and parameters are unique entities which both influence and define the structure and behavior of a system.
We define a variable as a component of our system that is subject to change due to its relationships and interactions to other variables and parameters.A variable does not have a defined value before our model is run. Its value is dependent on the parameters we choose, along with the structure and other components of the system.In our model, we may consider nearest neighbor distance (or nnd) to be a variable, because its value changes and entirely dependent on the values of our parameters, stochastic behaviors and other structures that define our model.
A parameter is a structure that is already ‘built-in’ to our system and is defined before the model runs. Parameters include our user-defined attributes: n_test, max_homes, ideal_density, nearest_neighbor_preference, aesthetic_quality_preference, and distance_service_center. Additionally, we could argue that the location of high-aesthetic-quality points and our initial center are parameters as they are predefined and influence the outcome of our model. We consider these to be parameters because they define the condition of the system. Parameter values do not change throughout the run of a model, and thus are not influenced by the dynamics of the model. A parameter’s value stays static throughout the run of the system and defines the landscape through which variables are influenced…
(Lots of) Visuals for parts 2 & 3:
<

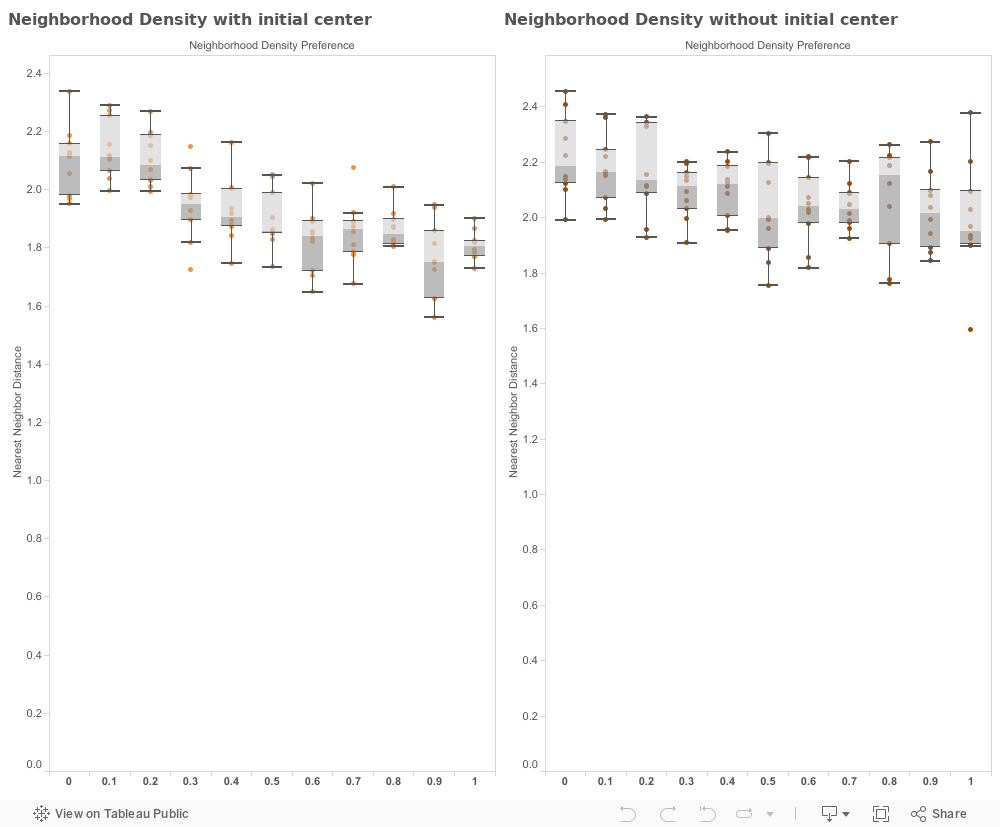
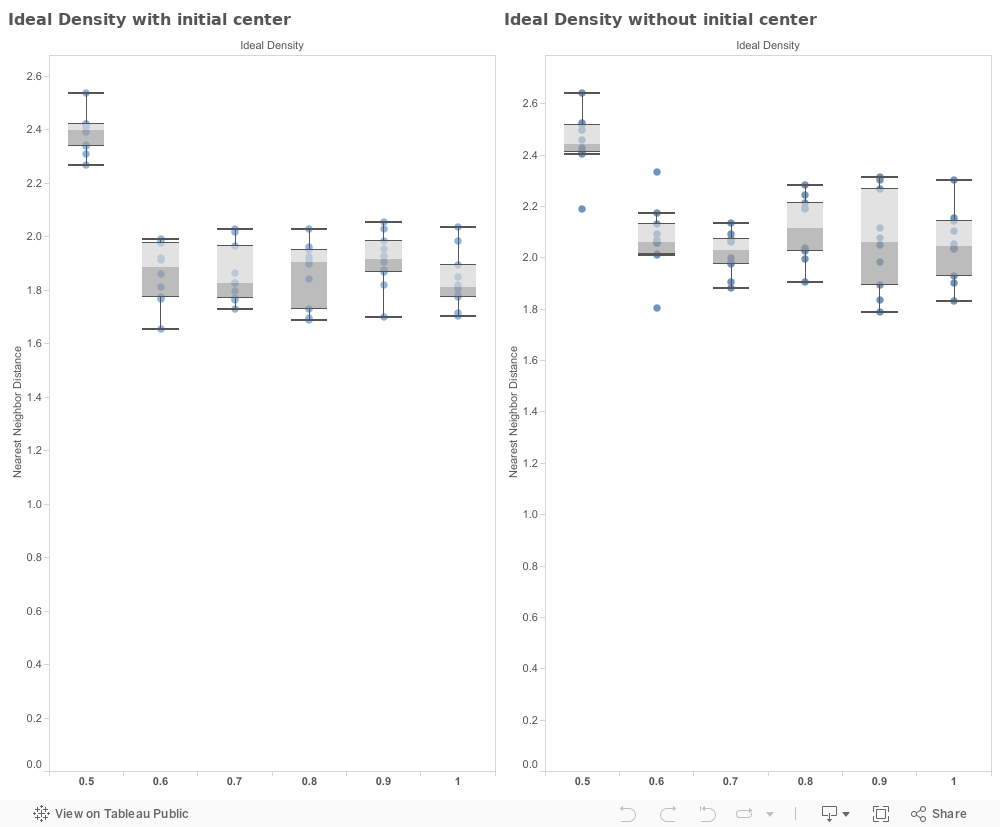
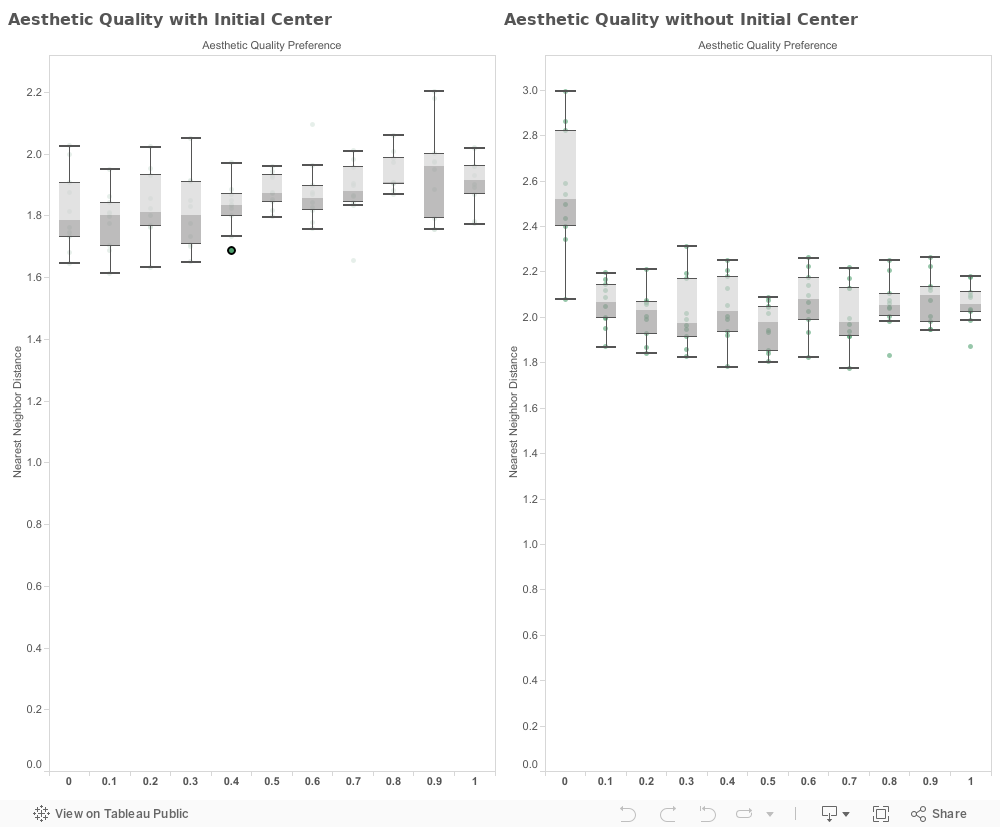
First off, it is important to note how this parameter sweep was conducted. To view the effects each parameter had on the nearest-neighbor-distance value, I kept all other values static throughout the duration of the sweep, with the exception of the initial-center parameter. This simplification was done to limit the amount of visualizations to ones that peak interest, while still preserving organization of the sweep. Visualizations were rendered in Tableau 9.0.
Part 2 (discussion): Which parameter is the nearest-neighbor distance most sensitive to? Why do you think this is the case?
We see that in the case where distance-service-preference is low, agents are drawn only to the area of aesthetic quality and thus create very dense clusters. These clusters form because agents entirely disregard their distance to services, the area of aesthetic quality is the only parameter determining the utility of a patch. Thus, agents will choose a patch closest to an area of high aesthetic quality.
In contrast, when distance to service is high, and when the environment is lacking an initial service center, agents cluster towards one area of high aesthetic quality, but are drawn away from the initial cluster as service centers are placed in the periphery of the point of aesthetic quality.
Part 3 (discussion): Which parameter is the nearest-neighbor distance least sensitive to? Why do you think this is the case?
By viewing the box plots above, we can see that the lowest variation in average nearest-neighbor-distance values occurred over the parameter sweep of aesthetic-quality-preference, when there was an initial service center in the environment.
This may seem unexpected, but makes sense when we view the parameter change’s spatial effects:


The urban clusters are staged in very different locations, but retain a similar density. If residents value aesthetic highly, they will cluster around one of two points. On average, half of the residents will cluster around each respective node, creating a moderately dense urban settlement. In the case where residents have no regard for aesthetic quality, they begin to cluster around the central node due to their existing distance-service-preference value. The reason the central cluster does not become more dense than the two smaller clusters is due to the additional placement of other service centers around the area. So as we can see, in either case, clusters or no clusters, agents will be around the same distance from one another.
Part 4: In our parameter sweep we used the mean nearest-neighbor-distance as an output descriptive statistic. Describe why nearest-neighbor-distance may be important to homeowners. List at least one other measurement that we could have used and explain how it differs from mean nearest neighbor-distance.”
We analyze nearest-neighbor-distance in our parameter sweep because this statistic gives us an idea to how urban clusters form–in either how dense or sparse they may be with respect to residential settlement. Essentially, the smaller nearest-neighbor-distance is, the more dense urban clusters are, and if the number is high, the opposite can be expected.
Since nearest-neighbor-distance is a variable, its value relies directly on the way we have defined our system through parameters and other structures and thus is able to give us insight into how parameter changes affect spatial patterns. Another variable that would sense the spatial patterns–though it is not (yet) written in this model–would be distances between service centers. Since service center placement occurs near areas of high residential use (or in this model, is placed directly near the nth home), we will be able to infer the density of urban clusters by how close service centers are to other service centers.
Part 5: In 100 words, what does the model describe with regards to how residential decision-making leads to specific patterns of urban growth.
The model illustrates that a number of different attributes affect residents’ decisions in choosing property and thus affects the spatial pattern of urban development. When the first few residents settle, and are drawn to a certain area of a landscape, urban clusters form around these points. The placement of service centers both influences and is influenced by residential clusters. Thus, this model shows how feedback, path dependence, and environmental heterogeneity and homogeneity can influence the placement, number and density of urban clusters across a landscape.