Posted on behalf of Scott Pratt (Executive Vice Provost) and Michael Dreiling (United Academics)
[embeddoc url=”https://blogs.uoregon.edu/casmetrics/files/2018/03/Metrics-MOU2-2277x2x.pdf” download=”all” viewer=”google” ]
Discussion about CAS Metrics
Posted on behalf of Scott Pratt (Executive Vice Provost) and Michael Dreiling (United Academics)
[embeddoc url=”https://blogs.uoregon.edu/casmetrics/files/2018/03/Metrics-MOU2-2277x2x.pdf” download=”all” viewer=”google” ]
Posted on behalf of Elliot Berkman (Psychology)
Ulrich Mayr from my department presented an idea for presenting narrative information alongside quantitative metrics with an annual State of the Department report. In a recent CAS Heads meeting, Ulrich brought up the idea of having a template for the SOTD report to introduce some standardization across departments. A template would also save departments some work by providing an outline of the kinds of content that the Provost is looking for.
I put together the draft template below. Departments could fill in the following sections then provide a full list of books, chapters, articles, grants, etc., in an appendix. In the end, the SOTD would resemble a kind of annotated departmental CV for each calendar year. (It seems like calendar year would be the easiest time frame given that most publications are dated by the year.)
Then the appendix would be a complete list of the activities and products related to each of these categories. I created a Google Doc of this template for easy sharing. One way to do this would be to have faculty copy-paste info from their CVs into the appropriate section of the appendix, then the Head and chairs of relevant committees would fill in the narrative components.
Posted on behalf of Elliot Berkman (Psychology)
A common theme that comes up in conversations about metrics is that they cannot be interpreted in isolation. For example, departments where faculty have unusually large service or teaching loads cannot be expected to maintain the same level of research productivity as departments where faculty have smaller loads.
I want to put in a plug for “contextualizing metrics” or other information about factors that influence scholarship productivity to be included alongside the departmental mission metrics.
Several candidates for contextualizing metrics have come up in various conversations. For example, it might be very helpful for consumers of your metrics to know about:
I emphasize that the point of these contextualizing metrics is not to provide a full accounting of your other activities (teaching, service, mentorship) — the Provost hopes to measure those, too, but not quite yet — but rather to give a more complete picture of how faculty in your department spend their time so the scholarship metrics can be interpreted with more nuance.
Posted on behalf of Scott Pratt (Executive Vice Provost, Department of Philosophy)
What?
Metrics (“indicators,” standards of measurement) as used here include two categories of information: Operational and Mission. The former are intended to provide information about faculty teaching workload and departmental cost and efficiency and the latter information about how well we are achieving our basic missions of teaching and research.
Operational metrics are aggregated at the College, School and department level and include SCH and majors per TTF and NTTF, number of OA and classified staff FTE per TTF, average and median class size, and degrees per TTF.
Mission metrics include data regarding undergraduate and graduate education (including serving diverse populations) and, still under development, data regarding faculty research.
Undergraduate data describes the undergraduate program in each college, school and department in terms of number of majors and minors, demographic information, major declaration patterns, graduation rates, and time to degree.
Graduate data describes the graduate program at the college, school and degree level in terms of completion rate and time to degree, demographic information, admission selectivity, information regarding student experience.
Research metrics (under development) are data regarding faculty research/creative activity productivity specific to each discipline and sub discipline where the data to be collected is specified by the faculty in the field. These so-called “local metrics” are intended to provide a faculty-determined set of measures that describe faculty work both quantitatively and qualitatively. It is clear that no single standard or number apply across all fields and so whatever metrics are produced, they will not be reducible to either a single standard or a single number.
It is important to note that research metrics will be revisable over time in response to changes in departments, disciplines and subfields, information available, and as we learn what are good and less good indicators of progress. The mode of reporting (also still under development) will likewise be revisable. (One approach to reporting is suggested by Ulrich Mayr, Psychology, on this blog.)
Note that PhD completion rate and time to degree is also reported by the AAU Data Exchange at the degree program level and so UO information can be compared with other degree programs at other AAU institutions. All other data is comparable over time and, in a limited way, comparable among departments (so that one could compare data within a school or college or among departments with similar pedagogy, for example).
Other graduate data is currently being collected through the AAUDE exit survey so that over the next several years sufficient data will be available to report PhD initial placement, graduate student research productivity (represented in publications), and data regarding student assessment of graduate advising support. These data will be available by degree program across all reporting AAU institutions.
Information about faculty service is not currently collected. Since service is a vital part of faculty work, we hope to develop a means of defining and collecting service data so that this can also be reported at the college, school, and department levels.
Why?
There are at least three reasons that operational and mission metrics will be collected. They are (1) external communication/accountability, (2) internal communication/continuous improvement/accountability, and (3) to provide information to help guide the allocation of limited resources.
Public research universities have a need for external communication that provides an account of their work to students and their families, the public, government agencies, disciplines and other constituencies. While the university already attempts to be accountable as a whole to its mission, it also has some obligation to be accountable in its parts. Diverse academic units support the mission of the university in different ways. A general accounting of the work of the university (which necessarily attempts to reduce the university’s work to a few standards) is insufficient to the latter task and so the ability to account for work accomplished at the department or disciplinary level is vital to ensure that our constituencies understand the value of both the whole and its parts.
Anecdotal information and “storytelling” are part of this effort, but so are systematically collected data. Whatever information is used to promote communication needs to be presented with explanatory information so that others will understand the differences between programs and what constitutes success. Data for external communications (such as student success data currently available to the public) must be limited to aggregated information and data sets that are large enough to ensure anonymity. Research metrics are important to this function because they provide a picture of what our faculty do, especially those programs whose work and expected results are less familiar to the wider public, legislators, and so on.
Internal communication is likewise essential both in order to ensure that university and college leadership understand the work done by faculty and so that departments themselves have a shared understanding of their work, needs, and the meaning of success. Communication with leadership needs to involve both a quantitative dimension that provides some idea of how much work is common in a particular field and how quality is defined for that field. Some of this information (e.g. student success data) is common enough across disciplines to suggest a general conception of quality using quantitative proxies (e.g. graduation rates), while other quantitative data (e.g. class size, research productivity) requires more explanation and narrower application.
Internal communication also concerns communication with faculty in helping make transparent department expectations for teaching and research. While review standards are often obscure, faculty nevertheless need a shared sense of what it means for faculty to be successful in aggregate in their fields. The development, implementation and regular review of metrics at all levels by faculty and administrative leadership provides a means to foster a shared vision of success; the ability to identify goals, opportunities, and problems; and determine how best to move forward.
Resources at every university are limited and allocating them requires both good information and good critical deliberation. Past budgeting systems have relied on formulaic systems that depend on reducing unit quality to two or three indicators for all programs (e.g. SCH, number of majors, number of degrees). Such an approach, when fully implemented, excludes aspects of department success that are not captured in the indicators. When not fully implemented, the need to allocate resources beyond what is partially specified by the limited set of indicators means that allocations must be made ad hoc. Rather than the reductionist approach taken in recent years, the current budget model aims to implement a deliberative model informed by both quantitative and qualitative data.
How?
How the metrics figure in the allocation process varies. In the Institutional Hiring Plan, the full complement of metrics is to be considered in deciding where particular TTF lines will be created. The IHP involves a structured review process involving department generated proposals, vetting by the school or college, review by the Office of the Provost, a faculty committee, and the deans’ council, with the final decision by the Provost.
In allocating GE lines, data regarding teaching needs is combined with graduate student success data and (when available) research data. Decision-making takes into account enrollment goals, student success data, other program data, and regular meetings with deans and Directors of Graduate Study.
The block allocation process (that establishes the base operating budget for each college and school) considers operational metrics and past budget allocations. Block allocations are proposed by the Office of the Provost and negotiated with the individual schools and colleges.
The strategic initiative process will consider in part data relevant to the proposals at hand (e.g. undergraduate success for proposals for undergraduate programs, graduate success data for proposals related to new program development). The initiative process involves a faculty committee with recommendations to the provost.
In general, use of the metrics will be guided by our goal to advance the UO as a liberal arts R1 university. This means that while there are other goals to be met (see below), meeting them must take into account the character and purpose of the UO as a liberal arts university.
Posted on behalf of Leah Middlebrook (Comparative Literature, Romance Languages)
One element that has risen to the top in our conversations about metrics, both here in the blog and at various meetings, is narrative. The Provost has requested a way to discuss and describe —i.e., narrate—the work we do in our departments and research units. It is interesting (and not surprising) to observe something of a consensus among colleagues across the sciences and the humanities with respect to how that narrative be assembled. Nearly all of us agree that databases and various kinds of quantitative reports give the illusion of transparency and objectivity, whereas in fact what one learns from the reports generated by means of these tools is guided by the narratives one draws from them. These narratives are subjective at some stage of the process: whether it is a person interpreting a report or a menu of filters that one selects in order to curate data, people, and their (our) opinions and judgments are involved —because ultimately, people write software, and groups of people edit and update that software (and forgive me if my training in lit. crit. inflects that short summary of how data and software work).
So the snapshots or views or talking points “generated” by databases and quantitative reports are as conditioned and inflected by human conscious and unconscious biases as are prose narratives. What is different between many kinds of quantitative and numbers-based reports and other kinds of evaluations is a lack of transparency regarding the minds and subjectivities that condition the rubrics, the filters and, hence, the findings and conclusions of those reports. This situation is problematic, generally, and it poses particular concerns when we have set inclusivity, equity and diversity at the heart of our mission to grow as a university and a community.
To the fine analysis and suggestions proposed elsewhere in this blog, I’d like to add that one solution to the challenges of unconscious and/or implicit bias is process. So the question I hope we can introduce into our discussion is What kind of process would facilitate productive, accurate and equitable evaluation of departments and campus units? As a second point: the university administration appears to be searching for an expedient way to look across units to evaluate and compare our strengths. That makes sense. We are all overworked. So: What kind of evaluative process will conform to our aspirations for equity and inclusiveness, while attending to the need for expediency?
This might be a good time to take a new look at the system by which universities across the U.S. collaborate in the work of reviewing candidates for tenure and promotion. The combination of internal and external evaluations, collected in a portfolio and evaluated with care by bodies such as our own FPC, has the virtue of being time-tested and ingrained in academic culture at a moment in which we are feeling the lack of congruence between how businesses (on the one hand) and academic and research institutions (on the other) conduct their affairs. For example, a colleague of mine pointed out recently that the academic context changes yearly as new subfields emerge and existing concerns / approaches / objects of study recede. Taking a snapshot in any given year freeze-frames evaluative criteria that should in fact adapt to changing intellectual horizons (horizons that faculty keep up with by reading in our fields). This acute observation underscores the importance and the value of faculty-based review. How often would an abstract, general metric need to be modified to keep up with how knowledges work “IRL”?
When I raised the model of external review recently, an objection was raised: Why would departments consent to having their research profiles evaluated by outside bodies? Wouldn’t they prefer to keep that information internal? The question was delivered in passing, so I am not sure if I understood it correctly, but my answer would be that to feed our information into databases is, in fact, sending it out for review. The advantage of working with committees and signed, confidential reports is that it is possible to trace the process by which judgements and opinions are formed, and also to ask questions.
I have worked on both the DAC and on the FPC, and am continually impressed by the professionalism, the thoughtfulness and ethics displayed by nearly all of those who undertake the work of serving on our committees or serving as external evaluators of a file. Furthermore, although I respect my colleagues to the skies (!!), I would maintain that the very good work that gets done through those processes is a function of their design. Each stage of the process of review builds from what has come before, but adds new perspectives and new opportunities to ask questions. The work of reviewing takes time and is, in the end, work –work that results, I hasten to add, in a fairly short report that goes to the Provost’s office. But this report is backed by a varied, well-organized file that carries layers of signatures and clear narratives of the process at every step of the way.
A good place to start on this process is the “State of the department” report proposed by Ulrich Mayr in this blog. Periodically (say, every three or five years), this report could go through a process of external review, undertaken via agreements with comparator institutions and departments. As in personnel cases, a number of reviewers would read and consider the department reports and prepare a confidential letter commenting on the strengths and relative standing of the unit with respect to the comparator pool. Finally, the file and letters would be reviewed and considered by an FPC-like body here on campus and a report would be issued to the Provost’s office. Given the fundamental importance of this work, and the priority we have placed as an institution on fostering equity, inclusivity and diversity, it is reasonable to expect that the university would commit funds to compensate work by the relevant committees and external evaluators (it seems likely that these funds would add up to less than the price of many software packages and database subscriptions).
Posted on behalf of Raghuveer Parthasarathy (Physics)
All departments at the University of Oregon are being called upon to create metrics for evaluating our “scholarship quality.” We’re not unique; there’s a trend at universities to create quantitative metrics. I think this is neither necessary nor good — in brief, quality is better assessed by informed, narrative assessments of activity and accomplishments, and the scale of university departments is small enough that these sorts of assessments should be possible — but I’ll leave an elaboration of that for another day. Here, I’ll point out that even a “simple” measure of research productivity, publications, is not simple at all, even applied within a single department. There’s nothing novel about this argument; similar things have been written by others. Still, since metric-fever persists, apparently these arguments are not obvious.
I think everyone would agree that published papers are a major component of research quality. Papers are what we leave behind as our contribtion to the body of scientific knowledge, our stories of what we’ve learned and how we’ve learned it. If one wanted some sort of quantitative measure of research activity, papers should undoubtedly figure in it. But how?
Similarly, one could argue that citations of papers are an important indicator of their impact on science. This seems straightforward to quantify — or is it?
I’ll illustrate some of the challenges in ascribing quality to content-free lists of papers or citations by looking at some example papers.
Here’s one:
[1] Raghuveer Parthasarathy, “Rapid, accurate particle tracking by calculation of radial symmetry centers,” Nature Methods 9:724-726 (2012). [Link]
As of today, this paper has been cited 205 times — a pretty high number. (I’m very fond of this paper, by the way; I think it’s one of the most interesting and useful things I’ve figured out, and it’s my only purely algorithmic / mathematical publication.)
Here’s another:
[2] G. Aad, T. Abajyan, B. Abbott, J. Abdallah, S. Abdel Khalek, A.A. Abdelalim, O. Abdinov, … , L. Zwalinski, “Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC,” Physics Letters B 716: 1-29 (2012). [Link]
This is from a physics department colleague, who is (by all accounts) an excellent scientist and a leader in his field. This paper has a stunning 11,201 citations! It’s also important to note that it has an even more stunning 2932 authors, with 178 different affiliations.
These are extreme examples, but they illustrate real differences between fields even within Physics. Biophysical studies typically involve one or at most a few labs, each with a few people contributing to the project. I’d guess that the average number of co-authors on my papers is about 5. High-energy physics experiments involve vast collaborations, typically with several hundred co-authors.
Is it “better” to have a single author paper with 205 citations, or a 2900-author paper with 11000 citations? One could argue that the former is better, since the citations per author (or even per institution) is higher. Or one could argue that the latter is better, since the high citation count implies an overall greater impact. Really, though, the question is silly and unanswerable.
Asking silly questions isn’t just a waste of time, though; it alters the incentives to pursue research in particular directions. If the goal, for example, is maximizing papers-per-author (or citations-per-author), this would reward hiring in areas like biophysics, or theory. If the goal is maximizing papers (or citations) in themselves, this would reward hiring in fields populated by large collaborations. If these metrics were applied everywhere, for example at the other research universities to which we like to compare ourselves, the net result would be an unintended shift towards some areas and away from others.
There are many other issues with counting papers or citations. Papers can be short or long, and norms of what constitutes a “publishable unit” differ between fields. Different journals have different (average) levels of quality, with high variance both between and within them. Some papers are initially highly cited and then forgotten, or the opposite. Despite a cottage industry of various indexes (h-indexes, impact factors, etc.), there’s no metric that captures all of this, nor have any of the existing metrics actually been assessed, as far as I know, as being good measures of “quality.”
Then, why ask for quantitative metrics? I really don’t know. Our university departments are small enough that, I would hope, our administrators have first-hand knowledge of what we’re doing and how well we’re doing it. Also, Physics and other departments do a pretty good (though not perfect) job of assessing what each faculty member is doing, through yearly narrative evaluations. These could be, and perhaps already are, conveyed to the higher-ups. Developing quantitative metrics of things like publications and citations is futile.
Is there anything positive I can say, towards having something “simple” to point to to guide the allocation of resources? If I were in charge, I’d pay more attention to external reviews of departments (which happen every decade or so, with little impact as far as I can tell), and also focus more on the small fraction of faculty who are unproductive by any measure, trying to construct carrots or sticks to enhance their activity. These would have a larger impact on the university’s research productivity than number-chasing.
Posted on behalf of Ulrich Mayr (Psychology)
As obvious from posts on this blog, there is skepticism that we can design a system of quantitative metrics that achieves the goal of comparing departments within campus or across institutions, or that presents a valid basis for communicating about departments’ strengths and weaknesses. The department-specific grading rubrics may seem like a step in the right direction, as they allow building idiosyncratic context into the metrics. However, this eliminates any basis for comparisons and still preserves all the negative aspects of scoring systems, such as susceptibility to gaming and danger of trickle-down to evaluation on the individual level. I think many of us agree that we would like our faculty to think about producing serious scholarly work, not how to achieve points on a complex score scheme.
Within Psychology, we would therefore like to try an alternative procedure, namely an annual, State of the Department report that will be made available at the end of every academic year.
Authored by the department head (and with help from the executive committee and committee chairs), the report will present a concise summary of past-year activity with regard to all relevant quality dimensions (e.g., research, undergraduate and graduate education, diversity, outreach, contribution to university service, etc.). Importantly, the account would marry no-thrills, basic quantitative metrics with contextualizing narrative. For example, the section on research may present the number of peer-reviewed publications or acquired grants during the preceding year, it may compare these number to previous years, or—as far as available–to numbers in peer institutions. It can also highlight particularly outstanding contributions as well as areas that need further development.
Currently, we are thinking of a 3-part structure: (I) A very short executive summary (1 page). (II) A somewhat longer, but still concise narrative, potentially including tables or figures for metrics, (III) An appendix that lists all department products (e.g., individual articles, books, grants, etc.), similar to a departmental “CV” the covers the previous year.
Advantages:
––When absolutely necessary, the administration can make use of the simple quantitative metrics.
––However, the accompanying narrative provides evaluative context without requiring complex, department-specific scoring systems. This preserves an element of expert judgment (after all, the cornerstone of evaluation in academia) and it reduces the risk of decision errors from taking numbers at face value.
––One stated goal behind the metrics exercise is to provide a basis for communicating about a department’s standing with external stakeholders (e.g., board members, potential donors). Yet, to many of us it is not obvious how this would be helped through department–specific grading systems. Instead, we believe that the numbers-plus-narrative account provides an obvious starting point for communicating about a department’s strengths and weaknesses.
––Arguably, for departments to engage in such an annual self-evaluation process is a good idea no matter what. We intend to do this irrespectively of the outcome of the metrics discussion and I have heard rumors that some departments on campus are doing this already. The administration could piggy-back on to such efforts and provide a standard reporting format to facilitate comparisons across departments.
Disadvantages:
––More work for heads (I am done in 2019).
Posted on behalf of Jenifer Presto (Russian, East European, and Eurasian Studies)
Here is information for calibrating local metrics in REEES. Perhaps the most important thing we have highlighted in our document is the fact that there are multiple ways of judging quality and impact aside from citations (peer reviews, course adoptions, appearance in syllabi and MA/Ph.D. reading lists) and that citations in a small field such as our own cannot be compared to citations in a larger field, even one with a similar methodology; they would need to be calibrated somehow to account for the size of the field.
[embeddoc url=”https://blogs.uoregon.edu/casmetrics/files/2018/03/REEES-METRICS-Mar-2018-yuya6j.pdf” download=”all” viewer=”google” ]
Posted on behalf of Greg Bothun (Physics)
Measuring impact of one’s peer reviewed publications is generally a highly subjective process and often it is assumed that if one publishes in the leading journals of their field, then those papers automatically have high impact.
Here I suggest a modest data driven process to remove this subjectivity and replace it with simple objective procedure that can be easily applied to Google scholars since the data is readily available.
This procedure basically involves using the time history of citations as an impact guide. The concept of ½ life is relevant here where after some paper is published there is some time scale over which ½ of its citations have occurred. Papers with longer ½ life, likely have had a larger impact. By way of example, we offer the following kinds of profiles:
Paper I: Published in 2005 which does not show decaying reference behavior but fairly sustained referencing over 12 years:
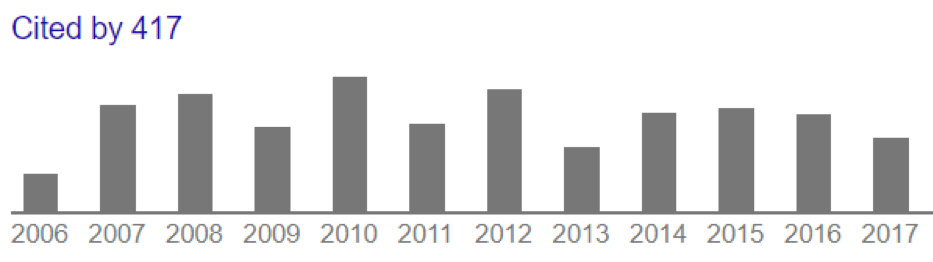
Paper II: Published in 1986 which shows quasi-constant referencing over a 30 year period (yes it sucks to be old):
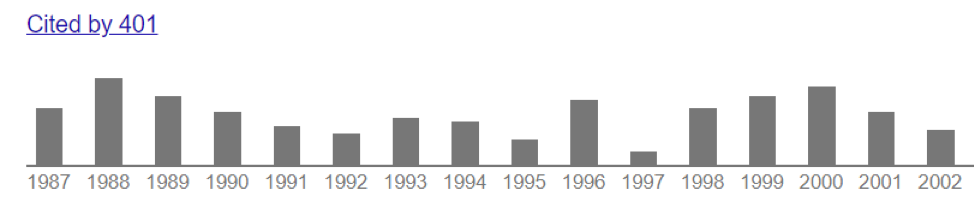


In terms of numbers, the period 2000 through 2011 contains ½ of the total citation number (244), while the other ½ occurred over the 6 year period 2012-2017. This is a qualitatively different citation history than the previous example.
Another example, this time on a small citation lifetime timescale, is shown below:
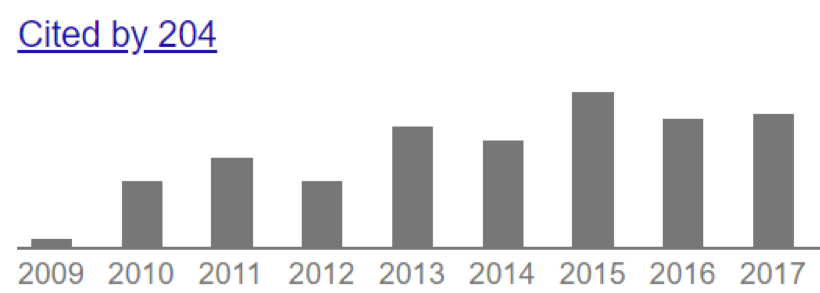
And here is an example of almost no impact early one, but the techniques described in the paper were discovered or emerged 10 years later:





For the latter case, although there is a long citation tail of low annual citations, ½ the citations were earned in a 5 year period near the time of publication.

I am not advocating that any of the above procedure be used, I simply saying that information in addition a raw number is available and can be used in some way to better characterize impact.
Posted on behalf of Elliot Berkman (Psychology)
Following on the article “Applying the Yardstick, Department by Department” that Dr. Bothun recommended on this blog, I was inspired to think through what a more faculty-driven set of metrics might look like. The article quotes Bret Danilowicz, Dean of CAS as Oklahoma State, on the metrics system they implemented there:
Mr. Danilowicz thought there was a better way, starting with getting lower-level administrators, department heads, and faculty members to participate in the assessment process every year.
“To me, the president and provost are too high a level for this,” he says. “If the goal is to give your departments a chance to take a good look at themselves, and with an eye toward improvement, you need to get faculty and chairs more involved in the process.”
A marine biologist by training, Mr. Danilowicz had served as dean of science and technology at Georgia Southern University. Now he wanted to understand the wider range of disciplines he was sizing up at Oklahoma State. It was important, he thought, to develop qualitative measures, not just numbers that could be mashed up.
“I’m a scientist, so grants and publications were very important to me,” he says. But as he talked with chairs and professors outside the sciences, he saw that each discipline brought its own yardstick.
“I came to learn that people in humanities want to review the quality of their scholarship. And arts people value creativity, which is really hard to measure,” he says. “The more I learned, the more it seemed natural to have the departments develop their own criteria and do their own assessments, and for my office to give them my thoughts on what they come up with.”
This process could start with a broad set of values and principles that can be different for each department. For example, in Psychology, I might articulate some of our values as the pertain to scholarship as:
Note that this is my personal articulation of some of our values and is not necessarily representative or universal. The set of values need to be a product of the entire department. I can imagine that having a series of high-level conversations within a department about what values it hopes to promote with its scholarship might be a useful and interesting exercise in its own right.
But, for now, let’s start with this initial set of values. How might these be translated into measurable variables? In psychology, for better or worse, the unit of scholarship is the peer-reviewed publication, typically in a journal. So, I can attempt to articulate ways that the values above could by translated into metrics on a per-paper level. For each paper, I can ask the following yes/no questions:
How would this work with actual papers? Here are a few recent papers from my lab with scores:
So what do I make of these ratings? As an author of these papers, this ordering (Cosme et al. > Giuliani et al. > Berkman) comports with my understanding of the “excellence” of these papers as I think of that term. Does this mean I think the Berkman (2018) paper is bad or low-quality? Not at all. In fact, I think there are some good ideas in that paper and that it might be influential in the field (a hypothesis I could test by watching how often it gets cited in the next few years). What is means is that the paper doesn’t advance my department’s values as much as the other two. I still get “credit” for it – it goes toward my publication count – but this system allows for a way to differentiate among my papers. The system prescribes a simple, moderately objective rubric for quickly assessing whether a paper promotes the values that I want to advance with my scholarship.
The incentives for our department are to publish papers that are in the journals we think are good; use diverse samples and authors; are authored by students and postdocs; are cross-disciplinary; and use open data and materials. I can game this system by publishing more papers like Cosme et al. Will I stop writing solo-authored theory pieces like the Berkman (2018) paper? No, because sometimes they’re fun and useful, and there’s not really a direct disincentive for me to write them (again, they still “count” and go on my CV and will be part of my p&t and merit review).
What would this process look like in practice? I can imagine that faculty score their own papers annually. When we send our CVs to CAS (which we already do each year), we could score all the new papers we published that year. Perhaps we could cap the score at some number, say 4, even if there are more than 4 values, so there are multiple ways for a paper to achieve the highest possible score. The departmental executive committee (or comparable), which already reviews files as part of merit reviews, could provide a sanity check on the scores produced by faculty.
At the department level, what we’d get is a count of total papers produced by the department that year, as well as an average values score for the papers in that department. Perhaps we could also supplement those metrics with some basic and readily available additional data such as citations and media mentions. Those decisions would be made at the department level.
In the end, the average values scores are not interpretable on their own. The would need to be contextualized primarily by year-over-year trends — as a department we want to see the scores go up next year — and possibly by similar data from comparator departments. We could gather that data for a small number of other departments ourselves, or, by making our process open and transparent, encourage other departments to start collecting themselves.